Chapter 7. 통계 기반 머신러닝 2 - 자율 학습과 지도 학습¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
| Authors: | Woong Jeong |
|---|
01 자율 학습¶
자율 학습¶
* 학습(學習)
사전적 의미 - 배움이라고도 하며, 직/간접적인 경험이나 훈련에 의해 지속적으로 지각하고, 인지하며, 변화시키는 행동 변화를 말합니다.
기계학습에서의 의미 - 계산을 반복하면서 가중치 계수를 업데이트해서 모델이 되는 기저 함수(바탕함수, basis function)와 분포에 가깝게 나타내는 것을 의마합니다.
* 자율 학습(Unsupervised Learning)
정답이 주어지지 않은 상태에서 학습을 통해 모델을 만드는 것. 통계에서 밀도 추정(Density Estimation)과 깊은 연관이 있다고 합니다.
클러스터 분석, 차원 압축 등을 주로 이용하여 그림으로 결과를 나타내는 등 사람이 데이터의 특징을 파악하기 쉽게 해주는 데이터 마이닝 기법이라고 할 수 있습니다.
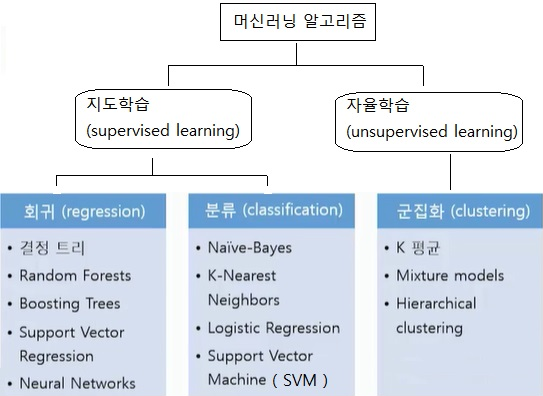
클러스터 분석과 K-평균 알고리즘¶
클러스터 분석(Cluster analysis)은 자율학습의 대표적인 접근 방법입니다. 주어진 데이터들의 특징에 그룹을 나누고 대표적인 특징을 찾아내는 방법입니다.
이를 통해 수 백만개의 데이터를 직접 확인하지 않고도 클러스터의 대표값만 확인하여 전체 데이터의 특징을 확인할 수 있습니다.
클러스터 분석의 대표적인 방법은 K-means알고리즘이 있습니다.
[k그룹 설정] -> [무작위 할당] -> [각 점에서 무작위로]
