Chapter 4. 가중치와 최적해 탐색¶
이 문서는 한빛미디어에서 나온 처음 배우는 인공지능 을 공부하면서 정리한 것이다.
01 선형 문제와 비선형 문제¶
두 변수의 상관관계¶
다수의 데이터에서 어떤 결과를 예측하는 경우 2개의 항목(변숫값)을 비교할 때가 많습니다. 2개 변숫값 각각을 그래프의 X축과 Y축값으로 정한 후 교차하는 곳에 점을 찍었을 때 분포는 선형과 비선형으로 나뉩니다.
선형 계획법¶
선형 계획법(Linear Programming) : 선형 함수를 이용해 점의 분포를 여러 개 그룹으로 나눌 수 있을 때 “선형 분리할 수 있다”고 하며, 선형 함수를 최적화해 문제를 해결하는 방법
비선형 계획법¶
비선형 계획법(Nonlinear Programming) : 변숫값 쌍으로 구성하는 점의 분포를 선형 함수로 표현할 수 없고 사상 개념(변숫값 쌍을 함수 형태로 변환한 것)으로 대응할 수 없는 비선형 문제를 해결하는 방법
- 볼록 최적화(Convex Optimization) : 볼록 함수와 오목 함수로 점의 분포를 나타낼 수 있는 볼록 계획 문제를 해결하는 방법
- 분기 한정법(BB : branch and bound) : 볼록 함수가 아닐 때 선형 계획 문제와 볼록 계획 문제를 조합하여 해결하는 방법
02 회귀분석¶
회귀분석¶
회귀분석 : 주어진 데이터로 어떤 함수를 만들어 낸 후, 이 함수를 피팅하는 작업. 피팅은 함수에서 발생하는 차이(잔차의 크기)가 최소화되도록 함수를 조정해주는 것을 의미.
단순회귀¶
- 요소들 사이의 비례 관계를 활용하는 가장 기본적인 회귀분석 방법.
- 회귀직선의 기울기와 절편 구하기
- y=a +bx+e 에서 기울기와 절편을 알면 임의의 x에 대한 결괏값 y를 얻을 수 있음.
- y : 종속 변수 (목적 변수), x : 종속 변수 (설명 변수), e : 오차항
- 단순 회귀 모델 식을 기반으로 잔차의 제곱인 E를 구하는 식 도출.
- E : 목적 함수
- a, b 각각의 편미분을 이용해 연립 방정식을 만들어서 잔차의 제곱인 E가 최소화되는 값을 구함.
- 연립 편미분 방정식을 풀면 a, b 각각을 구하는 식으로 변환 가능.
다중회귀¶
- 독립 변수가 한 개인 단순회귀와 달리, 여러 개일 때 사용하는 회귀분석 방법. y=a+bx1+rx2+e (x1, x2는 독립 변수)
- 독립 변수가 늘 때의 단점
- 다중공선성(Multicollinearity) 문제 : 독립 변수가 늘면 독립 변수들 사이에 존재하는 상관관계가 개입해 결과에 영향을 주는 것. PLS 회귀와 L1 정규화 등으로 해결가능.
- 다항식 회귀 : 산포도의 점 분포가 곡선 상에 위치하는 느낌을 받을 때 차수를 올려 대응하는 회귀분석 방법. 선형회귀의 한 종류.
- 과적합(Overfitting)의 문제점 : 차수를 올리면 잔차가 0에 근접할 수 있으나 이는 이미 주어진 데이터가 대상일 때 예측에 근접한 결과를 얻을 수 있고 앞으로 수집할 데이터를 대상으로 크게 벗어난 결과가 나올 가능성이 큼. 그러므로 회귀분석 할 때는 가급적 독립 변수가 낮은 차수를 갖는 모델을 설계하여 과적합을 피하는 것이 중요함.
- 최소제곱법 : 최소제곱법은 잔차 제곱의 합인 e값을 최소화하는 방법.
로지스틱 회귀¶
- 종속 변수에 약간의 수정을 가한 선형회귀. 일반화 선형 모델의 하나로 분류함.
- 로지스틱 모델의 일반식
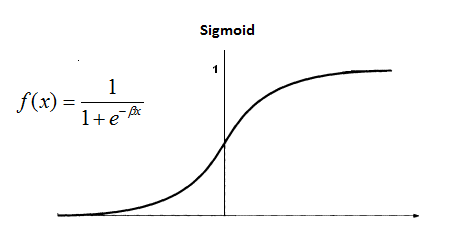
- 로짓(Logit) 변환 : 종속 변수 y에 로그를 적용해 y’로 변환하는 것.
- (http://www.saedsayad.com/images/ANN_Sigmoid.png)
{kind=link}
03 가중 회귀분석¶
최소제곱법 수정¶
- 최소제곱법은 특잇값(Singular Value)에 취약하다는 약점 존재.
- 특잇값에 패널티를 부여하거나 제외하는 방법 등으로 수정해야 함.
LOWESS(Locally Weighted Scatterplot Smoothing) 분석¶
- 어떤 한 지점에 가중회귀 함수를 사용해 평활화(smoothing)를 실행한 회귀 식 도출 방법.
- 임의로 설정한 폭 d(x)가 있을 때, xi의 최솟값부터 차례로 값을 증가시키면서 x에 가까운 xi 값이 되도록 가중치 wi를 산출함.
- 독립 변수의 값에서 멀어져 있는 점의 기울기를 조절함으로써 특이점 때문에 받는 영향을 무시하도록 보정하는 것.
로버스트 평활화¶
- 평활화를 실행하는 과정에서 특잇값을 없앨 수 있도록 가중치 계수 w를 설정하는 방법.
- 중위 절대편차(Median Absolute Deviation, MAD)를 산출했을 때 6배 이상의 잔차 ri가 존재하면 wi를 0으로 설정함.
- 변화 상태에서 크게 벗어났다고 예상되는 점이 특이점 때문에 받는 영향을 무시하도록 보정하는 것.
L2 정규화, L1 정규화¶
- 최소제곱법으로 구성한 방정식에 panelty를 부여하는 것.
- L2 정규화
- 최소제곱법의 종속 변수인 잔차 제곱의 합에 가중치 계수인 w1 제곱의 합을 panelty로 추가한 것.
- 능형회귀(Ridge Regression)라고도 함.
- 회귀 모델로 계산함.
- L1 정규화
- 종속 변수에 wi 절댓값을 panelty로 더해줌.
- Lasso (Least Absolute Shrinkage Selection Operator)라고도 함.
- 볼록 최적화의 추정 알고리즘 사용함.
- 외부강의자료: 15쪽의 Example 을 보면 Ridge 와 Lasso 등을 왜 하는지 직관적으로 알 수 있음
- 참고자료: An Introduction to Statistical Learning 의 chap6 를 보면 좀 더 자세히 알 수 있음
04 유사도¶
유사도¶
- 변숫값 쌍이 얼마나 ‘비슷한가’ 확인하는 과정은 컴퓨터가 자동으로 답을 추측하는 과정에서 매우 중요함.
코사인 유사도¶
- 유사도 : 변숫값 x, y가 주어졌을 때 cosθ의 값.
- 범위 : 0 ~ 1 (유사도가 높을수록 1에 가까워짐)
- 문서 사이의 유사도를 계산하는데 사용됨.
- 단어목록 n : 유사도를 요구하는 문서 1과 문서 2의 모든 단어로 구성.
- x : 문서 1의 단어가 나오는 빈도 (i = 1, 2, …, n)
- y : 문서 2의 단어가 나오는 빈도 (i = 1, 2, …, n)
- 변숫값 쌍은 산포도를 사용해 점의 집합으로 나타낼 수 있으며, 점 각각은 원점으로부터의 벡터로 나타낼 수 있음.
상관계수¶
- 상관관계 : 2개의 확률 변수 사이 분포 규칙의 관계 (한 쪽이 증가하면 다른 한 쪽도 증가하고, 한 쪽이 감소하면 다른 한 쪽도 감소하는 것.)로 대부분 선형 관계의 정도를 의미함.
- 피어슨 상관계수
- r : -1(음의 상관계수) ~ 1(양의 상관계수)
- 절댓값 0.7 이상이면 상관관계가 있다고 판단.
- 스피어만의 순위 상관계수
- 피어슨 상관계수의 특별한 경우. 같은 순위가 있다면 순위를 보정해야 하지만, 적을 때는 순위 보정 필요없음.
- 켄달의 순위 상관계수
- 같은 순위인 데이터의 개수 K, 다른 순위인 데이터의 개수 L을 사용하여 계산.
- r : -1 ~ 1
상관함수¶
- 함수의 유사도를 구할 때 사용하는 방법.
- 특정 시점의 결괏값 쌍으로 상관계수를 구한 후 이를 함수로 나타낸 것.
- 교차상관함수 : 두 함수에서 어떤 시점의 두 함수 결괏값 쌍의 상관계수를 구해 함수로 나타내는 것.
- 자기상관함수 : 두 함수가 같은 함수일 때 서로 다른 시점의 함수 결괏값 상관계수를 구할 때 사용함.
- 함수의 주기성 검증
- 합성곱 처리
- 푸리에 변환 등의 신호 처리에 사용
거리와 유사도¶
- 거리가 가까울수록 유사도가 높다.
- 편집 거리(Edit Distance)
- 치환, 삽입, 삭제의 세 가지 요소에 각각 panelty를 설정하는 형태를 취하고 panelty의 합계를 점수로 설정해 유사도를 구하는 방법.
- 레벤슈타인 거리(Levenshtein Distance)
- 값이 아닌 문자열 사이의 유사도를 나타낼 때 사용하는 방법.
- 영어 단어의 검색 서비스
- 해밍 거리(Hamming Distance)
- 고정 길이의 이진 데이터에서 서로 다른 비트 부호 갖는 문자 개수.
- 2개 비트열의 배타적 논리합을 구한 결과에 존재하는 1의 개수.
- 오류 검사, 유전자를 구성하는 염기서열이나 아미노산 서열의 상동성을 계산하는데 사용
- 유클리드 거리
- 2차원 분산형 차트에서 변숫값 쌍의 관계를 표현할 때 점 2개의 좌표 사이 직선거리를 의미.
- 마할라노비스 거리 (Mahalanobis Distance)
- 유클리드 거리에서 점 수를 늘려 거리를 구하는 것.
- 데이터의 상관관계를 고려한 여러 개의 점 집단에서 어느 점까지의 거리를 계산.
- 자카드 계수
- 집합 2개의 유사도를 구할 때 집합 2개의 공통 요소 수를 전체 요소 수로 나눈 것.